
Migrating from MySQL to ClickHouse: simplifying our analytics pipeline

For a long time, we used MySQL to power our publisher analytics. Like many teams, we built OLAP-style cube tables — each designed to answer a specific question: "How many installs per campaign?", "What's the revenue per user per campaign?", etc.
This approach worked at first but became increasingly painful to maintain. Eventually, we decided to migrate our analytics infrastructure to ClickHouse. Here's how we did it, what changed, and what we learned along the way.
The problem with OLAP cubes
In our old setup, every incoming event triggered updates to multiple pre-aggregated tables (OLAP cubes). Each cube table represented a fixed combination of dimensions and metrics.
For example, a "revenue" event would update tables like:
- revenue_by_type
- revenue_by_campaign
- roas_by_type
- roas_by_campaign
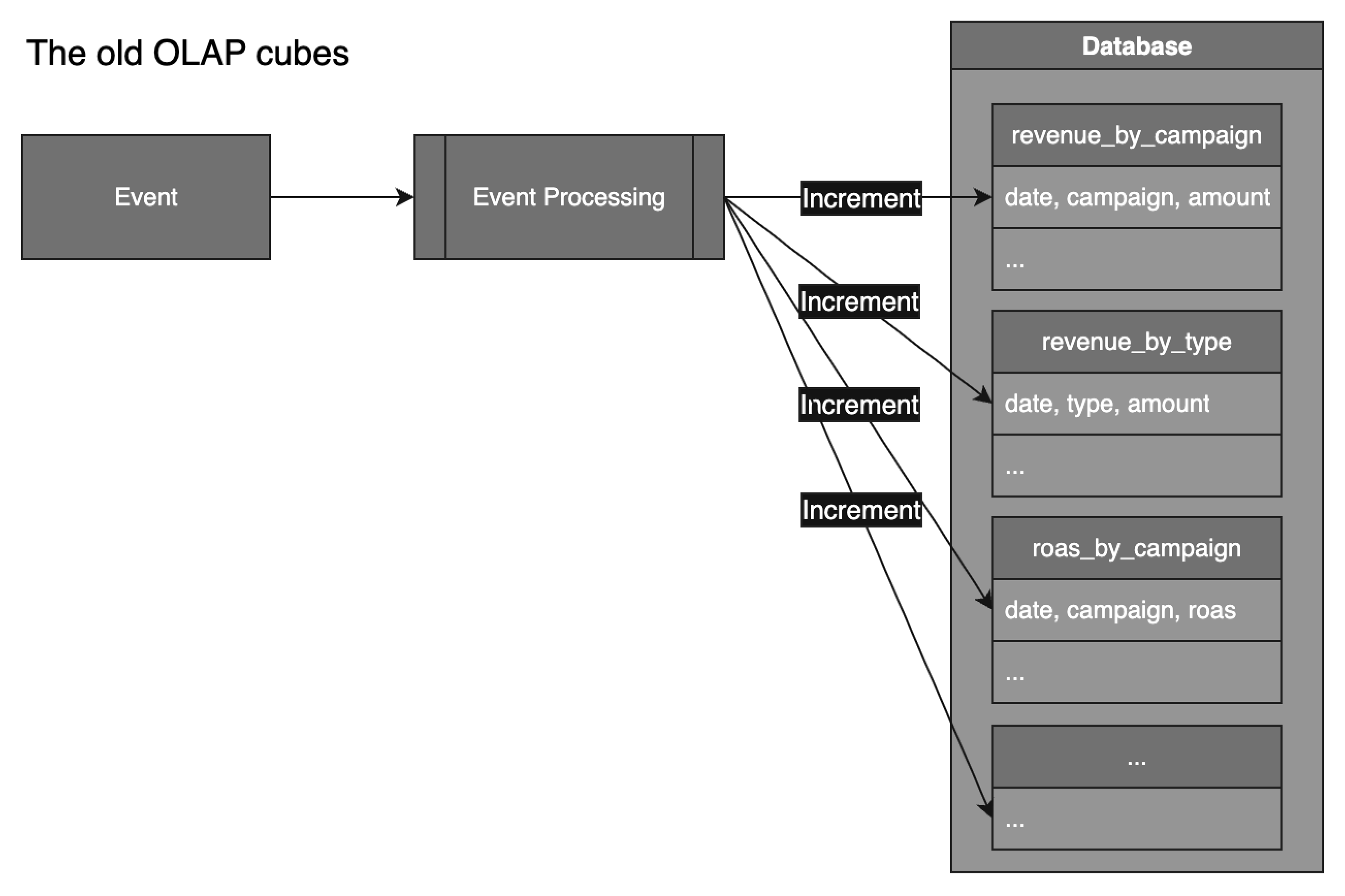
This system had serious limitations:
- Difficult to extend — every new dimension or metric required schema changes and more tables.
- Difficult to debug — investigating incorrect counts across derived tables was a headache.
Why we chose ClickHouse
We needed something faster, more flexible, and easier to maintain. After some research, ClickHouse stood out for several reasons:
- High performance on analytical queries, even on raw, event-level data.
- Simpler data pipelines — no need to pre-aggregate metrics.
- Schema flexibility — ideal for wide, denormalized event tables.
We opted for a full migration (rather than a hybrid approach) and set a goal to deprecate the MySQL-based pipeline entirely.
Migration strategy
The migration was planned and executed over the course of a couple of months. Here's how we approached it:
- Started with dual write, so both MySQL cubes and ClickHouse received the same events. This allowed us to compare results and ensure accuracy.
- Replaced dozens of cube tables with a single raw events table in ClickHouse.
The migration was smooth, with no major technical challenges.
The new model: raw event table
Instead of splitting metrics across many cube tables, we now write each event once into a denormalized event table.
We also store the full raw event payload as JSON, which gives us flexibility to extract new fields later without reprocessing old data.

Example
{
"event_type": "revenue",
"user_id": 123,
"country": "US",
"campaign_id": 456,
"revenue_amount": 120,
"timestamp": "2025-08-07T12:03:00Z",
...
}
| event_type | user_id | country | campaign_id | revenue_amount | timestamp | raw_payload (JSON) |
|---|---|---|---|---|---|---|
| revenue | 123 | US | 456 | 120 | 2025-08-07 12:03:00 | {…} |
We can now answer questions like:
SELECT country, campaign_id, sum(revenue_amount)
FROM events
WHERE event_type = 'revenue'
GROUP BY country, campaign_id
No pre-aggregation required. No schema changes. No duplication.
Results
The migration to ClickHouse gave us immediate and lasting benefits:
- More flexibility — new dimensions, metrics, and reports can be added instantly.
- Better developer experience — simpler schemas, fewer moving parts.
- Queries are fast, but we still need to design the database schema properly to keep them optimal.
Lessons learned
- Start with dual write to validate results without risk.
- Store raw payloads as JSON to future-proof your schema.
- You likely don't need a full ETL pipeline — simple scripts can go a long way.
Final thoughts
Moving from MySQL cube tables to ClickHouse was a big shift, but it was worth it. We've gone from complex data pipelines to a system that's fast, flexible, and easy to work with.
If you're struggling with maintaining OLAP cubes or scaling analytics on general-purpose databases, ClickHouse might be the answer.